7 minutes, 12 seconds
Intro

For some time now, really since last November, I’ve wanted to do two things: Encrypt all my DNS traffic leaving my house LAN and run an instance of Pi-Hole to reduce ads spamming my browser (and running cryptocurrency mining software ;). As well, even if you’re connecting to a web server over HTTPS, your DNS lookups are still in the clear free to monitor, monetize or possible mangle. I thought I wanted to do this on a single, small single board computer. I even bought a few of these sweet Orange Pi Zero boards to run it on!
However, in the end I realized I already had a dual core/quad thread i3 NUC running my ownCloud instance, and I could leverage that to run some of my favorite software: LXD! See my previous write up on setting up LXD so that your containers get an IP accessible on your LAN.
LXD
Once you have LXD set up, then we can create two containers with two static IPs on your LAN, one to run the awesome ad-blocking Pi-Hole and anther to run Stubby which we’ll use to run an encrypted DNS tunnel to Quad9. Quad9 is the semi-new DNS service that does not log, is very fast and is anycasted to over 100 locations world wide. Full disclosure, I work for PCH which sponsors Quad9.
To make provisioning Ubuntu instances easier in LXD, I have this bash script which I’ve cobbled together from various sources:
#!/bin/bash
# SEE https://gist.github.com/ser/1d214423c7387d9c7528a8c1df71c6f3
# Create LXD container
#
if [ $# -eq 0 ]
then
echo "create.new.lxd.container.sh \$NAME \$IP \$GATEWAY \$PROFILE"
echo "create.new.lxd.container.sh myvm 10.0.40.100 10.0.40.1 member"
echo " or "
echo "create.new.lxd.container.sh myvm 10.0.40.100 10.0.40.1 default"
exit
fi
###### VARS
NAME=$1
IP_4=$2
GATEWAY=$3
PROFILE=$4
DNS=9.9.9.9
###### NETWORK CONFIG
NC="#cloud-config
version: 1
config:
- type: physical
name: eth0
subnets:
- type: static
ipv4: true
address: $IP_4
netmask: 255.255.255.0
gateway: $GATEWAY
control: auto
- type: nameserver
"
lxc launch ubuntu: $NAME -c user.network-config="$NC" -c user.user-data="$UC" -p $PROFILE
My LAN has a subnet of 192.168.68.0/24, so I used these two calls to make my two LXD instances:
create.new.lxd.container.sh pihole 192.168.68.20 192.168.68.1 default
create.new.lxd.container.sh stubby 192.168.68.21 192.168.68.1 default
Now my (only 2 (for now ;)) LXD containers are running and ready with static IPs:
# lxc list -c n,s,4
+--------+---------+----------------------+
| NAME | STATE | IPV4 |
+--------+---------+----------------------+
| pihole | RUNNING | 192.168.68.20 (eth0) |
+--------+---------+----------------------+
| stubby | RUNNING | 192.168.68.21 (eth0) |
+--------+---------+----------------------+
Pi-Hole
The Pi-Hole folks have made the install awesomely easy. You just run this one liner after connecting to your Pi-Hole container:
curl -sSL https://install.pi-hole.net | bash
Of course, you shouldn’t just trust random commands you copy and paste from the Internet, so you can git clone from their repo as well. During the install, you can choose what ever DNS provider you want as we’re going to change it. Otherwise, accept all the defaults. Do notice the admin password at the end – you’ll need this!
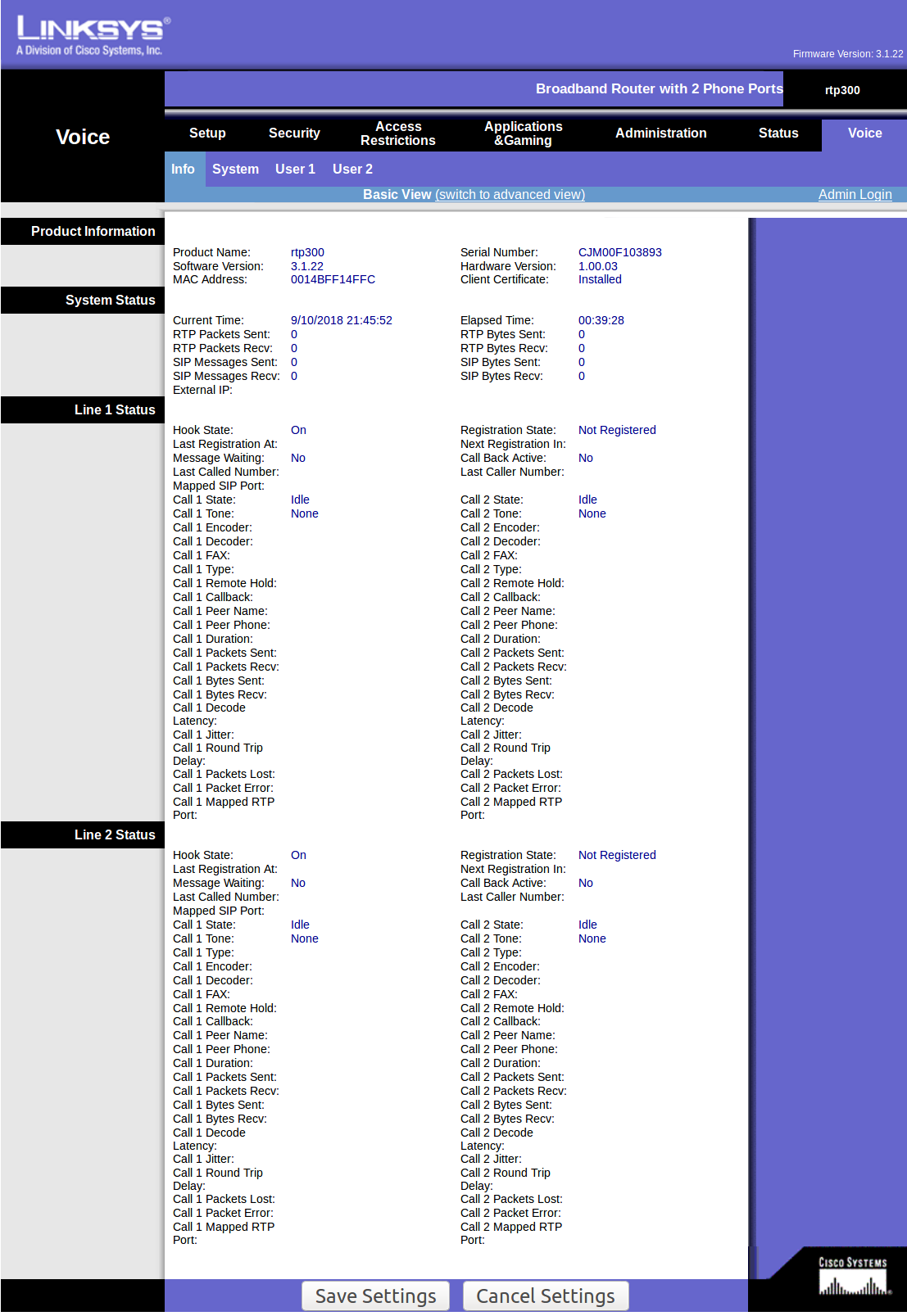
After the installer is done, you should be able to to your Pi-Hole IP to log into the admin web GUI. For me this is at https://192.168.68.20/admin. After you’re logged in, go to the DNS settings page. For me this is http://192.168.68.20/admin/settings.php?tab=dns.
Once here, change “Interface listening behavior” to “Listen on all interfaces, permit all origins”. As well, change “Upstream DNS Servers” to be only the IP of your stubby container. For me this is 192.168.68.21:

Now let’s go set up stubby at 192.168.68.21!
Stubby
I’ve found a number of guides that show you how to install both Pi-Hole and Stubby on the same box, often a Raspberry Pi. While convenient to not have more hardware on your network, they also have to hack Pi-Hole to see Stubby. The reason is that Pi-Hole can’t talk to anything but port 53 on which ever IP your specify. The hack is then to get dnsmasq that Pi-Hole uses to talk directly to Stubby. The Pi-Hole GUI cannot see this change and it may get overwritten on Pi-Hole upgrades. The fact that I could have 10 or 20 containers and I’d still run the same amount of hardware coupled with the fact that the config (see Pi-Hole section above) is all done cleanly and upgrade safely in the GUI, made me use two discrete containers.
This Stubby install guide below is 99.99% not mine, so please thank redditor SphericalRedundancy and his comment about setting up Stubby on Ubuntu. Thanks SphericalRedundancy! The changes I made is to move another comment about running ldconfig as a key component of the install and remove Pi-Hole specific changes. Oh, the other change is that I want to run Stubby on port 53 which is a privileged port, so I run Stubby as root instead of creating a new user (stubby).
Install build & run time dependencies
sudo apt install -y build-essential libssl-dev libtool m4 autoconf
sudo apt install -y libev4 libyaml-dev libidn11 libuv1 libevent-core-2.0.5
Build Stubby
git clone https://github.com/getdnsapi/getdns.git
cd getdns
git checkout develop
git submodule update --init
libtoolize -ci
autoreconf -fi
mkdir build
cd build
../configure --prefix=/usr/local --without-libidn --without-libidn2 --enable-stub-only --with-ssl --with-stubby
make
sudo make install
Configure stubby.yml
cd ../stubby
cp stubby.yml.example stubby.yml
sed -i.bak '/ - 127.0.0.1/,/ - 0::1/{/ - 0::1/ s/.*/ - 127.0.2.2@2053\
- 0::2@2053/; t; d}' stubby.yml
sudo /usr/bin/install -Dm644 stubby.yml /etc/stubby.yml
Configure stubby.service
cd systemd
echo ' ' > ./stubby.service
sed -i '$i [Unit]' ./stubby.service
sed -i '$i Description=stubby DNS resolver' ./stubby.service
sed -i '$i Wants=network-online.target' ./stubby.service
sed -i '$i After=network-online.target' ./stubby.service
sed -i '$i [Service]' ./stubby.service
sed -i '$i ExecStart=/usr/local/bin/stubby -C /etc/stubby.yml' ./stubby.service
sed -i '$i Restart=on-abort' ./stubby.service
sed -i '$i User=root' ./stubby.service
sed -i '$i [Install]' ./stubby.service
sed -i '$i WantedBy=multi-user.target' ./stubby.service
Install stubby service
sudo /usr/bin/install -Dm644 stubby.conf /usr/lib/tmpfiles.d/stubby.conf
sudo /usr/bin/install -Dm644 stubby.service /lib/systemd/system/stubby.service
Edit host file
sudo sed -i '/127.0.2.2/d' /etc/hosts
sudo sed -i '/0::2/d' /etc/hosts
sudo sed -i '$i 127.0.2.2 Stubby' /etc/hosts
sudo sed -i '$i 0::2 Stubby-v6' /etc/hosts
Add path to libgetdns library & running ldconfig
sudo sed -i '$i LD_LIBRARY_PATH=/lib:/usr/lib:/usr/local/lib' /etc/environment
sudo /sbin/ldconfig -v
Enable and run stubby service
sudo systemctl enable stubby
sudo systemctl start stubby
Clean up
cd ../../../
rm -rf ./getdns/
Quad9
Before we configure Stubby to use Quad9’s DNS over TLS service, let’s test everything to make sure it’s working. From the Stubby container, let’s make sure Stubby is working by running sudo systemctl status stubby. My output looks like this:
● stubby.service - stubby DNS resolver
Loaded: loaded (/lib/systemd/system/stubby.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2018-04-20 17:32:27 UTC; 2 days ago
Main PID: 14731 (stubby)
Tasks: 1
Memory: 2.8M
CPU: 13.951s
CGroup: /system.slice/stubby.service
└─14731 /usr/local/bin/stubby -C /etc/stubby.yml
Apr 20 17:32:27 stubby systemd[1]: Started stubby DNS resolver.
Apr 20 17:32:27 stubby stubby[14731]: [17:32:27.969574] STUBBY: Read config from file /etc/stubby.yml
Apr 20 17:32:27 stubby stubby[14731]: [17:32:27.970478] STUBBY: DNSSEC Validation is OFF
Apr 20 17:32:27 stubby stubby[14731]: [17:32:27.970498] STUBBY: Transport list is:
Apr 20 17:32:27 stubby stubby[14731]: [17:32:27.970506] STUBBY: - TLS
Apr 20 17:32:27 stubby stubby[14731]: [17:32:27.970515] STUBBY: Privacy Usage Profile is Strict (Authentication required)
Apr 20 17:32:27 stubby stubby[14731]: [17:32:27.970522] STUBBY: (NOTE a Strict Profile only applies when TLS is the ONLY
Apr 20 17:32:27 stubby stubby[14731]: [17:32:27.970529] STUBBY: Starting DAEMON....
All good! Now let’s ensure DNS lookups are working using the default DNS servers with a dig call, again while logged into your Stubby instance:
dig @127.0.2.2 -p 2053 quad9.net +short
216.21.3.77
Sweet! So if we use port 2053 on the localhost IP of 127.0.2.2, Stubby is listening and relaying the DNS lookups. All good.
Now edit /etc/stubby.yml so this section:
listen_addresses:
- 127.0.2.2@2053
- 0::2@2053
Looks like this:
listen_addresses:
- 192.168.68.21@53
- 127.0.2.2@2053
- 0::2@2053
Again, swap out the 192 IP with what ever IP you’re using for your Stubby instance. Now find *all* the sections after upstream_recursive_servers: in that same file and ensure that only Quad9 is there:
upstream_recursive_servers:
- address_data: 9.9.9.9
tls_auth_name: "dns.quad9.net"
Removing all comments and empty lines, my complete stubby.yml file looks like this (thanks to this handy grep call: egrep -v '#' /etc/stubby.yml |grep -v -e '^$'):
resolution_type: GETDNS_RESOLUTION_STUB
dns_transport_list:
- GETDNS_TRANSPORT_TLS
tls_authentication: GETDNS_AUTHENTICATION_REQUIRED
tls_query_padding_blocksize: 128
edns_client_subnet_private : 1
idle_timeout: 10000
listen_addresses:
- 192.168.68.21@53
- 127.0.2.2@2053
- 0::2@2053
round_robin_upstreams: 1
upstream_recursive_servers:
- address_data: 9.9.9.9
tls_auth_name: "dns.quad9.net"
Now let’s restart Stubby and make sure it still works with another dig command (again, use your Stubby IP where the 192 IP is), but this time we don’t specify a port so the default 53 is used:
sudo systemctl restart stubby
dig @192.168.68.21 plip.com +short
192.81.135.175
All good! Finally, we already configured the Pi-Hole instance to use .21 (but you use your IP!) so we can test the full round trip by running a dig call against it which will, int turn, use the Stubby proxy:
sudo systemctl restart stubby
dig @192.168.68.20 plip.com +short
192.81.135.175
The final step is to configure your router to hand out 192.168.68.20 as the DNS server. Each router is different, but for me, I run pfSense, so I changed it there under “ServicesDHCP -> ServerLAN” and then on the page under “DNS servers” I entered just my Pi-Hole IP (you enter yours though, not mine!) of 192.168.68.20
Now you can enjoy ad blocked, unlogged, encrypted DNS on your home LAN – w00t!





 As part of putting some
As part of putting some 





 Like before I was luck to have my work send me to
Like before I was luck to have my work send me to