1 minute, 16 seconds
This post is a short parable told in three lessons:
Lesson 1: The web is not as temporal as you might think!
Recently a co-worker was travelling and was unable to access her work based email. Instead, she directed folks to email her at her personal email. Being a curious fellow, I clicked over to her personal site to see what she had to say. All I found was “Site in progress, check back later” and link to a very outdated resume. Well, that’s just no fun! Enter the wayback machine! Using this fine site, I was able to see all the text, photos and links she had long since redacted. The wayback machine never forgets, so don’t you forget that.
Lesson 2: Robots.txt can pull Jedi mind tricks.
A natural response to seeing the archive of other sites, is to see what dirt folks might find out about me via the same method. Sure enough, there’s some good stuff! However, the more interesting fact I learned is that my robots.txt of today redacted the archive.org copy of yesterday! This is cool! A while ago I took down my resume and some older, more personal content and as well took a sec to make some broad strokes of search engines shouldn’t index. It was these actions that archive.org took note of. With a wave of my robots.txt hand, indeed these are not the pages you’re looking for.
Lesson 3: The wayback machine is way cool.
Ok, this parable kinda peters out right about here, but still, the wayback machine is way cool. Check out the rad looks plip.com has had over the years! Hrm, maybe that should be “rad”. You decide.
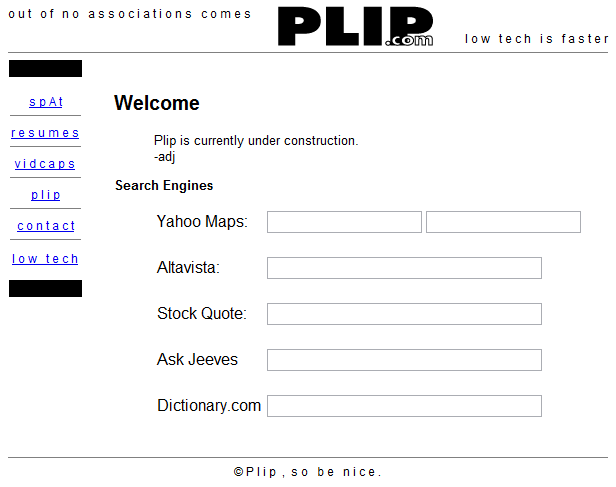
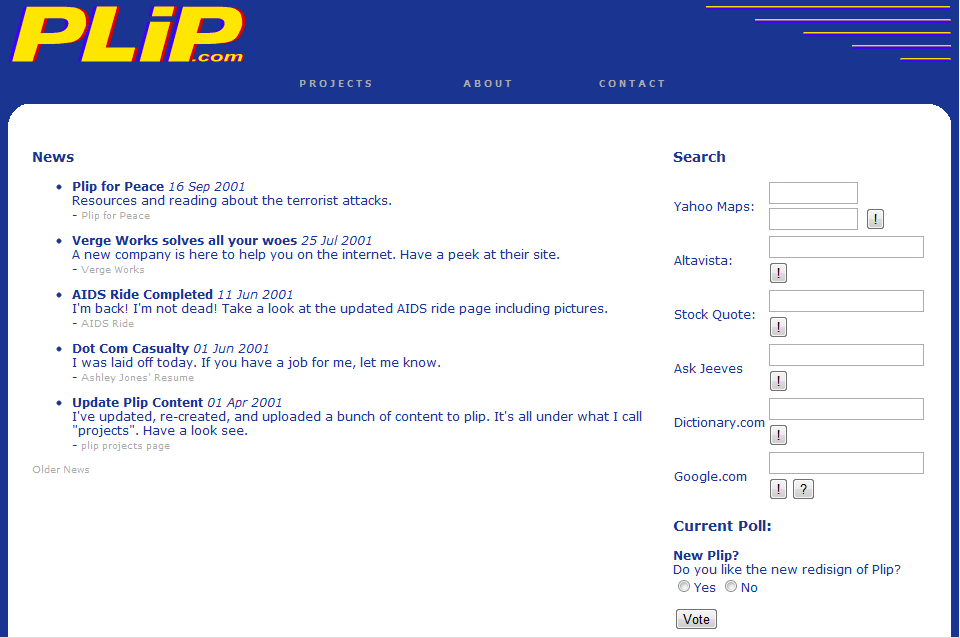

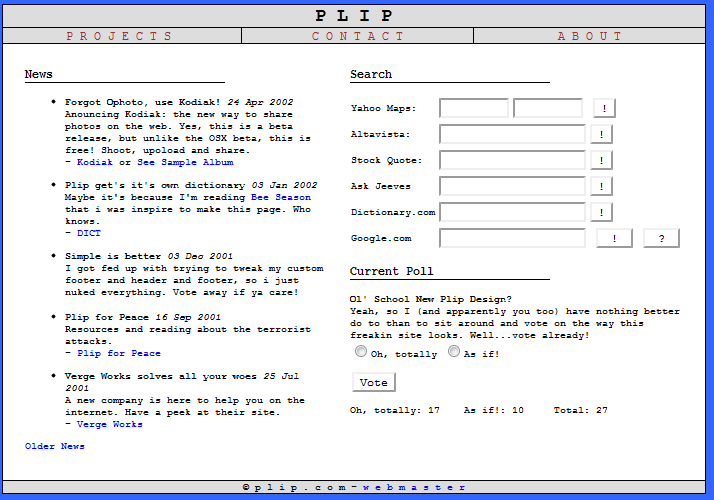

You should know that I find a man who correctly uses the word “temporal” *very* attractive.
So you approve? W00t!
Nice reminder. Went “wayback” and looked at my site. Started it in 1999… argh… that’s starting to make me sound old :)
Looking way back, I enjoyed this old race report. Congrats on the win 8 years later ;)
http://www.hanskellner.com/archives/2002/06/18/race_report_2002_wheels_of_thunder_criterium.html