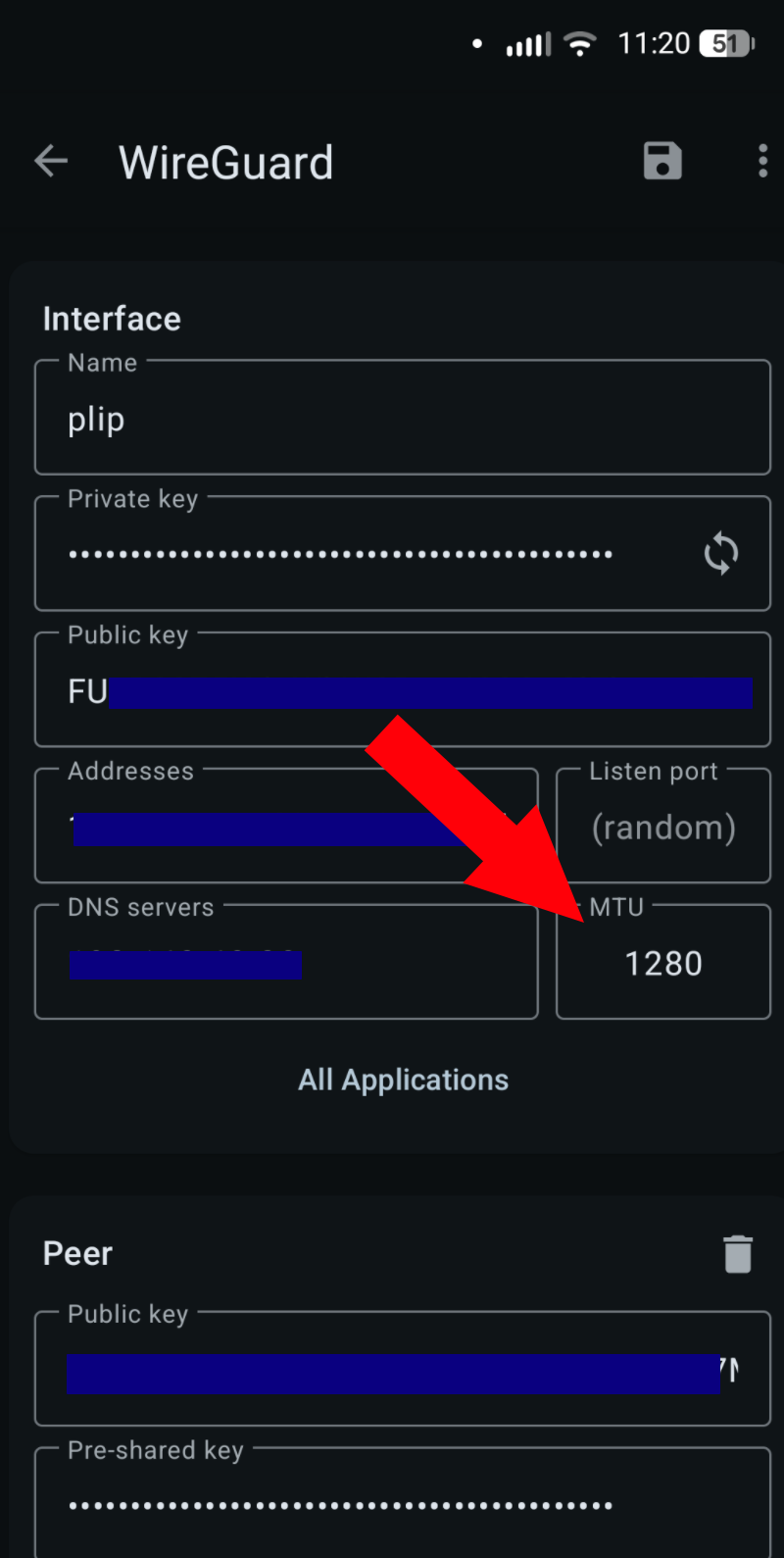
Change your MTU from 1420 to 1280 if your Android device is having issues connecting to your Wireguard VPN over cellular data. This MTU value should work on both WiFi and cellular data.
Slowly discovering the solution
For some time now I’ve been baffled why my Wireguard VPN doesn’t work on my phone. I was a looser and not actively troubleshooting it, so instead I spent months slowly unraveling what is going on with these discoveries:
I found my phone VPN didn’t work – odd – that’s frustrating
A few weeks later, I realized that my laptop worked fine. OK, so it’s endemic to the phone – noted
A few weeks after that I had a big breakthrough – my VPN on my phone worked on WiFi but did not work on cellular data. So odd!
Finally, one morning over a tasty coffee, I started DDGing for something like wireguard not working on mobile data, works on wifi
I found a Reddit post (not this one, but like this one) that said changing the MTU can fix this issue
There’s a trope among computer nerds that any complex problem that you’re struggling to figure out WTF is going on, was probably caused by DNS. There’s a whole slew of sites that capture this sentiment including itwasdns.net , itwasdns.io/was-it-dns, itwasdns.org and it’s even available as a T-Shirt!
Wait – was it DNS?
I was recently reminded of “it was DNS” during a server upgrade I was doing. For the self-hosted setup I run at home, I have two identical Ubuntu servers. This allows me to easily move services between the two servers to do potentially destructive maintenance on one and the other will still be up and running. This prevents family from complaining, “The Internet is down!! I need the Internet!!!” (which of course has never happened…noooope, no self inflicted internet outages here).
In preparation for the Ubuntu 22 -> 24 upgrade I’d been putting off, I had just moved the main file server and the DNS server (Nextcloud, Pi-Hole and Stubby) from primary to backup servers. Notably, the services keep the same IP address on either server.
After moving all the services, I checked that both DNS and Fileserver were working, like the good little sys admin I am. I completed the Ubuntu uplift from 22 to 24 (hello sudo do-release-upgrade). After the uplift completed, I stopped the services on the backup server and started up on the main server. I immediately checked if DNS worked – all good there! Then I checked Nextcloud. Nope, down on the desktop. Um… a little panic is setting in… Ah hah! I’ll double check on another device – my phone! Also not working there. Ok, stomach just dropped, sinking feeling that I’ll have to fail back over to backups and have a day of troubleshooting ahead. Ugh.
Parenthetical aside: Why might it be DNS
(The title of this blog post already tells how this story ends, but let’s have a brief interlude to talk a little bit about DNS works. For a big explainer, I highly recommend Julia Evan’s DNS blog post series (or her DNS Zine!). Specifically, her post DNS “propagation” is actually caches expiring is especially applicable here. Otherwise, when your client queries a DNS server it hands back a “time to live” (TTL). This is then cached locally for the TTL duration. A common value might be 3600 (60 minutes) or possibly 86400 (1 day). Parenthetical aside over!)
Back to our hero fighting a possible outage and fail-over to backup
I was baffled how the file server was unavailable. I the used digtool to check from 3rd system that wasn’t my desktop or my phone. Something odd happened: it resolved fine. What!?! I then did a curl to the Nextcloud URL and it worked perfectly.
This was baffling.
When things get baffling I try to artificially induce a shower thought. I stepped away from the keyboard, took a deep breath and played a game of boggle.
180 seconds later, with no shower thoughts forming over boggle, I retraced my steps. And then it hit me: I didn’t refresh the backup of the DNS server! Aha!! An NXDOMAIN no doubt was cached. Here was my theory
I deployed the Nextcloud server on the main server, including a Local DNS Host entry – an A record that only works on my home LAN on my Pi-Hole. The A records has a TTL of 0
Notably, I did NOT sync the Pi-Hole to the backup server
In preparation of bringing down the main server, I copied the file server’s data to the backup server and then started the file server and DNS server on the backup.
I tested both DNS and file server worked, presumably using a client cache of DNS*
I upgraded Ubuntu 22 -> 24
Somewhere in here, both my phone and my desktop, running the Nextcloud clients, queried the out of sync Pi-Hole for the Nextcloud IP.
Since there was no A record for Nextcloud, the Pi-Hole dutifully returned an NXDOMAINresponse with a TTL of 3600 to both my phone and my desktop.
Upgrade completes in 10 minutes later, I stop services on the backup server, start them on the production server
Nothing works
I feel terrible
So if I had just synced DNS to the backup server, my two main clients wouldn’t have had the problem on step 7 above.
Conclusion
The most baffling thing of all of this, and a bit embarrassing to only find out now, is this fact:
Records added using [local DNS] feature always get served with TTL=0
Wait…what?! So every query to local DNS records on my LAN are NEVER cached?! Further, NXDOMAIN entries are cached for a full hour?! This is a big DNS footgun! Every successful lookup is rewarded with a request to please check again the very next time you need to know this address. Every failed lookup is cursed to remember that failure for an hour. Yay?
In the end, I’m going to change my TTL of local DNS records to be 3600 like a sane person. And I’m going to be extra sure my DNS is synched to my backup server first!
May the next SysAdmin benefit from my failures ;)
Postscript
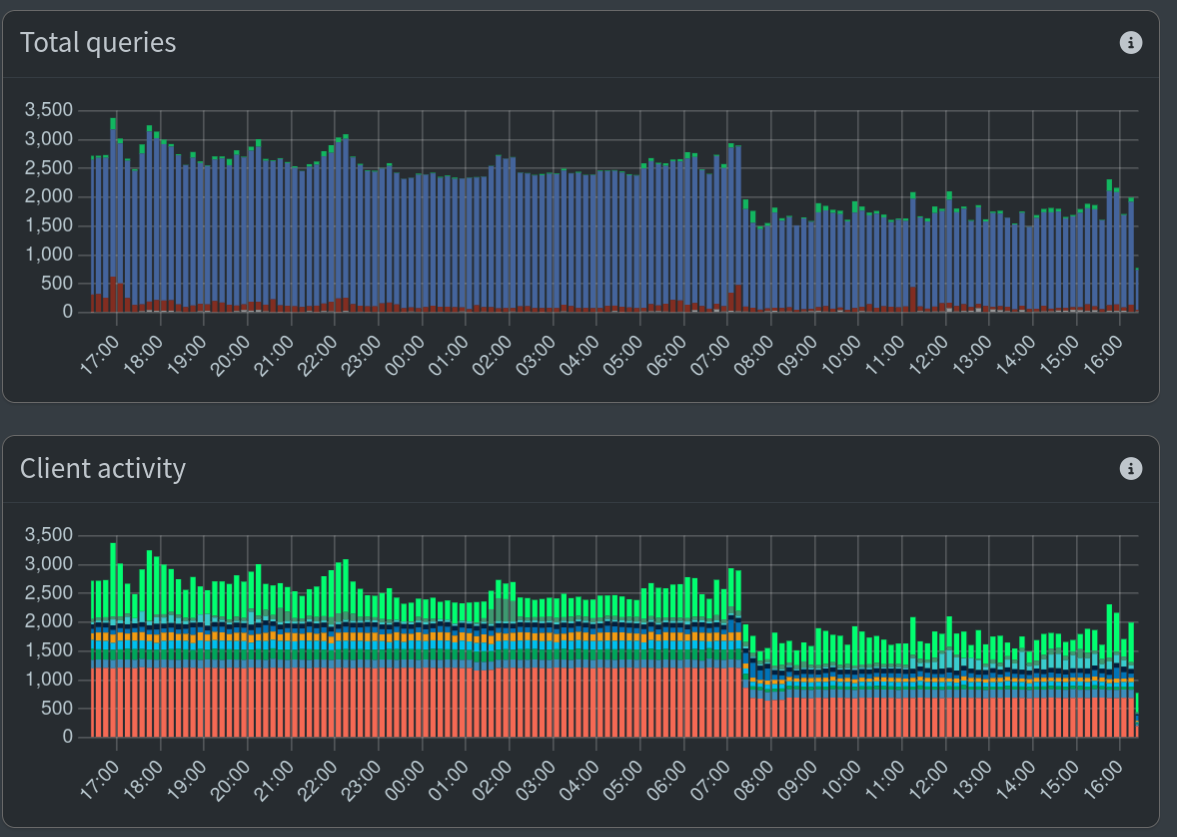
Some hours later I checked the Pi-Hole admin dashboard and was happy to see that the queries had gone down quite a bit (see graph at the top of the post). However, I’m still not 100% sure why it didn’t go down dramatically more. If every query is cached for 60 min where before it was never cached, I would have expected a bigger drop.
In the end queries take 5ms or less (see dig and the Query time result) and the load average on the server is really good (0.07, 0.13, 0.18) so it’s OK if I solve this problem another day!
* I’m also not sure why, at the end of the “Wait – was it DNS?” section why the tests didn’t fail immediately. If before the move, all DNS lookups were not cached and after the move the backup DNS server didn’t have the fileserver entry, it should have failed immediately. Input from my dear readers welcome!
A quick post to spread the love about the watchcommand – it’s amazing!
Prior to your knowledge of watch, maybe you wanted to run a command every 2 seconds, like say hello (credit to SO for this one):
$ while true
> do
> echo "hello"
> sleep 2
> done
But this is tedious and awkward. Maybe you collapse into the ol’ bash oneliner:
while true; do echo "hello";sleep 2;done
This is a small improvement, but A better way is with watch!
watch echo "hello"
So much nicer, right?! Watch runs any command you follow it with ever 2 seconds – boom!
But the real power comes when your checking the progress of something over time. Maybe you want to see when the login for a website comes backup with a 200 ? You’d of course reach for curl, but it’s a pain to run over and over. Again, watch makes short work of this:
But the real REAL REAL power, in my opinion, is when you want to do multiple things at a time. So instead of switching back and forth between terminals to do so, just chain them together with a bit of echo for spacing. This makes it trivial to watch the load average, get the last few lines of a debug log and tail a docker container all in one spot like so:
The beauty of this Is that I started quickly with just one command running in watch. Then I could iteratively add another one and anothe rone. The longer the job ran, the more I could add in, like the nice labels in echo and such. I’m SSHed in to a remote server and I’m tmux`ed up to my neck and in one of the panes, this watch job dutifully runs, keeping “watch” on all things (see what I did there?).
The fact that watch handles the refresh (configurable too!) and redraws the content in place without any flickering is just lovely! watch on!!
I have a Framework 13″ (Ryzen 5 7640U w/ 2.8K Matt screen) that has USB-C PD charging like most modern laptops. While it normally ships with a 60W USB-C charger, I’ve gotten away charging it with a teen tiny 45W charger – this is because Framework is totally awesome and went out of their way to support very low watt chargers. I love it!
To this end, I wanted an emergency teeny tiny battery that I could use on every device I own. Be it an old kindle with microUSB, my kids’ iPhone with lightening port or, yes, you guessed it, my whole laptop that, for what ever reason, I desperately need to charge or use for a bit more.
After doing some research, I found an open box deal for $20 on an Anker 30W battery. While I knew that Framework went out of it’s way to be compatible with less than perfect chargers, I was nonetheless quite pleased to see it all working. I kitted out my emergency charge kit with an 8″ USB-C <> USB-C cable, a USB-C <> lightening adapter, a USB-C<> microUSB adapter and a USB-C <> to USB-A adapter for good measure. I just keep it charged up in the bottom of my bag – so handy just in case!
Set a flatpak env variable and run a CLI call to grant permissions. Jump down to “the fix” at the bottom to see how or read on for a little backstory!
The quest
For a while now I’ve been really loving daily driving Bluefin on both my laptop and my desktop. However, one of my biggest complaints, coming from running Xorg, is that my very most favorite screenshot utility doesn’t work on the desktop: Flameshot. Easily installed via a flatpak, it either errors out prompting on permissions or looks like it’s gonna launch but doesn’t. Strangely, I found It Just Works™ on my laptop which led me to think it was multi-monitor issue as my desktop is three up affair ( | | — if you must know).
Every now and again I try the work-arounds and they never work. Then today I was doing some work which required arrows on screenshots, the absolute happiest of paths for Flameshot. I thought I’d fumble through with some of the work-arounds to see if any of them worked.
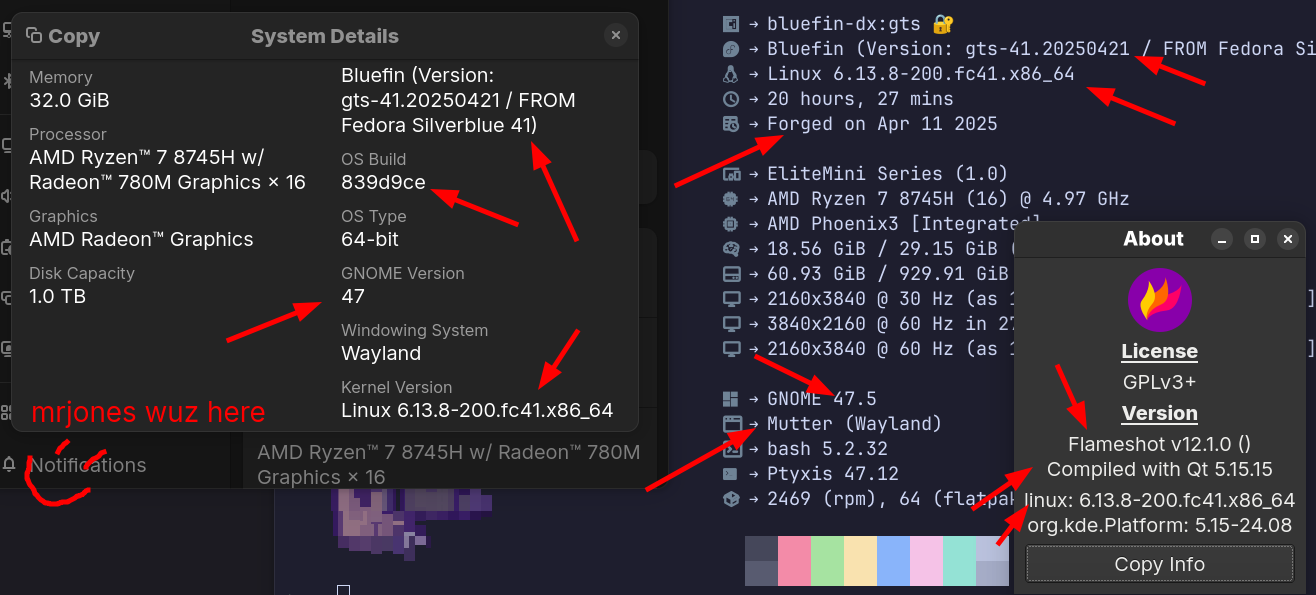
Surprise surprise, I made two changes and it works! I’ll keep this post updated, because some times things change and it breaks, but as of right now, it just works works. Here’s a screenshot with like a bazillion arrows (remember, it works!! happy path!!) with some relevant versions:
(for the SEO types, thats: Gnome 47, OS Build 839d9ce, Bluefin (Version: gts-41.20250421 / FROM Fedora Silverblue 41) and Bluefin (Version: gts-41.20250421 / FROM Fedora Silverblue 41), Flameshot v12.1.0 () Compiled with Qt 5.15.15)
For some time I’ve had all my home lab systems running on LXD. For me at least, LXD predated Docker and so I’ve stuck with it. The containers are a bit more pet like and less cattle like – but that’s OK. They’re there for me to learn with – plus I can totes do docker in LXD inception if I wanna! (I’ll figure my way over to Incus some other month)
So years and years ago I found out bout FreshRSS as a great way to self host an RSS reader. This meant I didn’t have to install any apps on my phone, my feeds could stay synced and since I already had a VPN setup, it was trivial to access while on the road. Lovin’ it! I’d set this up around late 2018.
Fast forward to yesterday, I flippantly upgraded FresshRSS to the latest, as I occasionally do, and the site started having a fatal error, as it often does after I upgrade ;) I pulled up the error logs on the FressRSS LXD container running Apache and MariaDB and immediately saw some sort of unexpected { character in function blah blah on line 1-oh-smang-thirty error. Huh, what’s that about?
Turns out in the latest dev release of FreshRSS, they’d formally removed support for PHP 7.x and required PHP >8.0. Specifically, this was because they’re using Union Types in their function declarations. This is cool stuff! you can see the int|string values in the sample function here:
// Declaring a function with Union Type
function getMixedValue(int|string $value): int|string {
return $value;
}
This is no problem! I’ll just update PH….P…. oh yeah – I’m on hella old Ubuntu 18…so then I’ll just find some third party apt repo and add that and then…. Hrrmm…might be more trouble than it’s worth. That’s cool! I’ll just deploy a new Ubuntu container on 24.04. Oh, well, that’s gonna take a chunk of disk space – I’ve been using a bit of Alpine to build small Docker images at work, what about a pet Alpine in LXD? They have an image – why not!
Preparing the leave the old system
Before we sudo rm -rf / on the old box (er, container), let’s get our data outa there. We need to first make a dump of the database. We’re root so we can just zing right through any permissions with a one liner. Next up we can zip up our old files into one big ol’ honkin zip file. That looks like this:
mysqldump freshrss > ~/freshrss.sql
cd /var/www/localhost/htdocs/
zip -r ~/freshrss.zip .
Finally, we can generate an SSH key for this root user to easily copy to the new container – I knowingly didn’t add a password because I’m about to delete the container and we’re all friends here:
That’s it! You’re now sitting as root on the new instance. Let’s install the base packages including Apache, MariaDB, OpenSSH and PHP with all it’s libraries:
As final hurrah at the old server, now that our SSH key is on the new server, let’s copy over the zip archive and the SQL dump. Be sure to replace 192.168.68.217 with your real IP!
scp ~/freshrss.* 192.168.68.217:
Go SQL!
Now that we have our server with all the software installed and all the data copied over, we just need to pull together all the correct configs. First, let’s run setup for MariaDB and then harden it. Note that it’s called mysql… , but that’s just for backwards compatibility:
That last command will ask questions – default answers are all good! And the initial password is empty, so you can just hit return when prompted for the current password. Maybe check out passphraseme if you need a password generation tool? Let’s add the database, user and perms now. Be sure to not use password as your password though!
echo "CREATE USER 'freshrss'@'localhost' IDENTIFIED BY 'password';" | mysql
echo "GRANT ALL PRIVILEGES ON *.* TO 'freshrss'@'localhost' WITH GRANT OPTIO" | mysql
echo "GRANT ALL PRIVILEGES ON *.* TO 'freshrss'@'localhost' WITH GRANT OPTION;" | mysql
Now we can load up the SQL and move all the PHP files to their correct home. Again, we’re root so no SQL password, and again, this is actually MariaDB, not MySQL:
Now find the one line where DocumentRoot is set and change it to this value and add two more lines. One to allow encoded slashes and one to set the server name. Be sure to use the IP address or FQDN of the server – don’t use rss.plip.com!
DocumentRoot "/var/www/localhost/htdocs/p"
AllowEncodedSlashes On
ServerName rss.plip.com:80
Now that apache has been configured, let’s restart it so all the settings are loaded:
rc-service apache2 restart
Conclusion
The old FreshRSS install should now be running on your new Alpine based container – congrats! This has been a fun adventure to appreciate how Alpine works as compared to Ubuntu. This really came down to two main differences:
systemd vs OpenRC – Ubuntu has usedsystemd for sometime now and the primary interface to that is systemctl. Alpine on the other hand usesOpenRC which you interface with rc-update and rc-service. Alpine picked this up from when it split off from Gentoo.
apt vs apk – Package management is slightly different! I found this to be an inconsequential change.
There’s plenty of guides out there that do the same as this one. Heck, you’re likely better of just using a pre-built docker image (though the topresults were pinned to PHP7)! However, I wanted to document this for myself and hopefully I’ll save someone a bunch of little trips off to this wiki or that FAQ to understand how to migrate off of Ubuntu to Alpine.
A while ago the battery on my NiteRider Swift 500 headlight stopped taking a charge. I looked at NiteRider’s FAQ page and saw no mention of the batteries being user serviceable. Further, when I searched online, I didn’t find any guides or replacement parts for the light. Time to grab a screwdriver and DIY!
I started by removing the strap mount – a single Phillips head on the bottom:
Then I removed the 4 allen screws around the base of the head:
The lens assembly should come off – be careful as the rubber battery cover will fall free now. Be sure to keep track of all the parts!
Remove the two Philips head screws at the top of the LED plate:
You should now be able to slide the LED plate out which is attached to the battery and the main circuit board. You’ll note the battery is both soldered on an aggressively affixed with double sided sticky tape. Peel the battery off, cut the two wires (one red, one black) half way between the battery and the circuit board. Rub the tape residue off enough so you can see the specs of the battery:
There’s no direct replacement part for this, but I found this “CaoDuRen Rechargeable 3.7V Li Lipo Lithium” on Amazon was close enough to work. Only $9 at the time – what a deal!
Cut the JST connector off of the new battery, cutting half way between the battery and connector. Solder the black to black and red to red wires, and seal up the solder connection. I used heat-shrink tubing and then affixed it with sticky Velcro:
Reassemble your light by following the steps above in reverse order. Careful when working with the light as it is quite bright and I had it accidentally turn on while assembling it – yikes!
Now enjoy your light and drop me a line if you have any other tips or succeed in replacing your battery!
A friend of mine created some fun stickers for use at the most recent DEF CON. They were sly commentary about how corporate a lot of the stickers are and how maybe we should get back to our DIY roots. But…what’s this? There’s a .xyz in there…is that a TLD…is there domain I could go to?! IS THIS STICKER AN AD ITSELF?!?!?!?!1!
It’s all of those things and none of those things – that’s why I love it so much. Best of all, when you go to website, you get just what you deserve ;)
The website was initially setup on a free hosting provider, but they didn’t provide any logs – something my friend was curious about to see how much traffic the non-ad ad was generating. I have a VERY cheap VPS server that already had Ubuntu server and Caddy on it, and I figured I could help by hosting a wee single file static web site and be able to easily offer the logs. Let’s see what we can do!
Step 1: One HTML file + Four Caddy config lines = Web server
I frickin’ love Caddy! I made a single index.html file and then added these 4 lines of config:
After I restarted Caddy (systemctl restart caddy) – I was all set! As DNS had already been changed to point to the IP of my lil’ server, Caddy auto-provisioned a free Let’s Encrypt cert, redirected all traffic from port 80 -> 443 and the site worked perfectly!
By default Caddy has logs turned off – let’s fix that!
Step 2: Turn up the (log) volume
Unsurprisingly, Caddy makes enabling logs very straight forward. Just add these three lines
I reloaded the config in Caddy (systemctl reload caddy) and checked for log activity in /var/log/caddy/. It was there! Oh…it was there in full repetitive, verbose JSON…OK, cool, I guess that’s a sane default in our new cloud init all JSON/YAML all the time world. However, how about common log format though?
This was the first time Caddy surprised me! While it was easy enough to do (huge props to “keen” on Stack Overflow), it was a bit more convoluted and verbose than I expected. You have to change the log deceleration to be log access-formatted and then specify both a format and a transform. The final full server config looks like this:
Now let’s figure how to to add secure access to download those logs.
Step 3: Rsync via Authorized Keys FTW!
A straight forward way to give access to the logs would be to create a new user (adduser username) and then update the user to be able to read the files created by the Caddy process by adding them to the right group (usermod -a -G caddy username). This indeed worked well enough, but it also gave the user a full shell account on the web server. While they’re a friend and I trust them, I also wanted see if there was a more secure way of granting access.
From prior projects, I knew you could force an SSH session to immediately execute a command upon login, and only that command, by prepending this to the entry in the authorized_keyfile:
If I had SOME_COMMAND be /usr/bin/rsync then this would be great! The user could easily sync the updates to their access log file at /var/log/caddy/the-domain-goes-here.xyz-access.log. but then I realized they could also rsync off ANY file that they had read access too. That’s not ideal.
The final piece to this Simple Single Page Site with Secure Log Access is rrsync. This is a python script developed specifically for the use case of allowing users to rsync only specific files via the Authorized Keys trick. The full array of security flags now looks like this:
As there’s no other logs in /var/log/caddy – this works great! The user just needs to call:
rsync -axv username@the-domain-goes-here.xyz: .
Because of the magic of rrsync (two rs) on the server forcing them into a specific remote directory, the rsync (one r) on client is none the wiser and happily syncs away.
Happy web serving and secure log access syncing and Happy Halloween!
Most of the time when I’m reading articles online, I very often switch my browser to Reader View. This gets rid of all fluff of display and theme that a site’s have and, most importantly, fixes the low contrast text trend. Reader View is white text on black background (but this is configurable) and also adds a “Time to Read” at the top of the article. The latter prevents me from clicking on a “quick read” which is actually 30 min!
I noticed some times I visit a site and don’t flip in Reader View because they’ve done it for me already! While I know not everyone is like me, so they may prefer miles of white space with a nice, thin, light gray font on an off-white background. However, as this is my blog, I’ve just converted to be just as I like those sites where I don’t turn on Reader View!
Referencing the image above, here’s’ the changes with the “before” on the right and the “after” on the left:
All code blocks are now numbered. They’re still zebra striped, but they’re higher contrast
Text is now larger and easier to read – straight up white on black
White background is now black background*
Items that are variables or code snippets have a different colored background, like this
The read time is shown at the top of every post (not pictured)
Removed “Share This” icons at the bottom of each post (also not pictured)
* – I actually don’t force the black background! All the changes are live based on the users’ OS preference via the prefers-color-schemeCSS selector. You can pick! Here’s a video showing the two flipping back and forth:
I’m still tweaking a few of the CSS colors and what not as I find things not quite right, but please send along any questions or comments. I’d love to hear what y’all think!
Addendum
The “Share This” plugin mentioned above was not only adding some extra clutter of icons I no longer thought too helpful, but was also including an external CSS or JavaScript or something file that didn’t feel right given I don’t prefer to share my HTTP traffic with any other sites.
As well, I removed two extensions (Share This and Code Highlighter syntax) which I then implemented in my own wee plugin. Less 3rd party code means less to update means less security concerns for my ol’ blog here. As well, I greatly reduced the feature set and amount of PHP – I think the plugin is about 5 active lines of PHP.
Finally, I’m using the Twenty Twelve theme with this additional CSS (added via “appearance” section of prefs):
At work we’ve written some monitoring and alerting software. We’ve also automated releases and we wanted to take it to the next level so that the instant there was a new release, we’d deployed to production. This automated releasing of software upon a new release is called Continuous Deployment, or “CD” for short. This post documents the simple yet effective approach we took to achieve CD using just 20 lines of bash.
The 20 lines of bash
Super impatient? I got you. This code will mean a lot more if you read the post below, but I know a lot of engineers want more copypasta and less preachy blog posts:
#!/usr/bin/env bash
# Checks for local version (current) and then remote version on GH (latest)
# and if they're not the same, run update script
#
# uses lasttversion: https://github.com/dvershinin/lastversion
current=$(cd /root/cht-monitoring;/usr/bin/git describe --tags)
latest=$(/usr/local/bin/lastversion https://github.com/medic/cht-watchdog)
update(){
cd /root/cht-monitoring
git fetch
git -c advice.detachedHead=false checkout "$latest"
/root/down-up.sh
}
announce(){
/usr/bin/curl -sX POST --data-urlencode "payload={\"channel\": \"#channel-name-here\", \"username\": \"upgrade-bot\", \"text\": \"Watchdog has been updated from "$current" to "$latest". Check it out at https://WATCHDOG-URL-HERE\", \"icon_emoji\": \":dog:\"}" https://hooks.slack.com/services/-SECRET-TOKEN-HERE-
}
if [ ! "$current" = "$latest" ];then
$(update)
$(announce)
echo "New version found, upgraded from $current to $latest"
else
echo "No new version found, staying on $current."
fi
Why use CD?
There’s been a lot written about CD, like this quote:
Engineering teams can push code changes to the main branch and quickly see it being used in production, often within minutes. This approach to software development [allows] continuous value delivery to end users.
I’ll add to this and say, as an engineer, it’s also extremely gratifying to have a pull request get merged and then minutes later see a public announcement in Slack that a new release has just automatically gone live. There’s no waiting even to do the release manually yourself, it’s just done for you, every time, all the time! Often when engineers are bogged down by a lengthy release process and slow customer adoption where it can take weeks or months (or years?!) to see their code go live, CD is the antidote to the poison of slowness.
Tools Used
The script uses just one custom binary, but otherwise leans on some pretty bog standard tools:
git – Since our app is in a local checked out git repository, we can use trivially find out what version is running locally with git describe --tags
curl – We use curl to do the POST to slack using their webhook API. It’s dead simple and requires just a bearer token
lastversion – I found this when searching for an easy and reliable way to resolve what the latest release is for our product. It’s on GitHub and it just made my day! It solved the exact problem I had perfectly and it really Does One Thing Well (well, admittedly also downloads)
down-up.sh – this is the cheating part of this solution ;) This is an external bash script that makes it easy tokeep track of which docker compose files we’re using. Every time we create a new compose file, we add it to the compose down and compose up calls in the script. This ensures we don’t exclude one by accident. It’s just two lines which are something like:
docker compose -f docker-compose.yml -f ../docker-compose-extra.yml down docker compose -f docker-compose.yml -f ../docker-compose-extra.yml up --remove-orphans -d
With all the tools in place, here’s how we cut a new release, assuming we’re on version 1.10.0:
An engineer will open a pull request (PR) with some code changes.
The PR will be reviewed by another engineer and any feedback will be addressed.
Once approved, the PR is merged to main with an appropriate commit message.
A release is automatically created: A fix commit will release version 1.10.1. A feat (feature) commit will release version 1.11.0. A commit citing BREAKING CHANGE will release version 2.0.0
Every 5 minutes a cronjob runs on the production server to compare the current local version verses the latest version on GitHub
If a new version is found, git is run to check out the latest code
The down-up.sh script is called to restart the docker services. We even support updates to compose files citing a newer tag of a docker image in which case docker downloads new releases of upstream. Easy-peasy!
A curl command is run to make a POST to the Slack API so an announcement is made in our team’s public channel:
Wrap up
You may become overwhelmed in the face of needing to store SSH private keys as a GitHub secret or having a more complex CD pipeline with a custom GitHub Runner. Don’t be overwhelmed! Sometimes the best solution is just 20 lines of bash you copied off a rando blog post (that’s me!) which you tweaked to work for your deployment. You can always get more complex at a later date as needed, but getting CD up and running today can be incredibly empowering for the engineers working on your code!